On Gans
What are GANS?
As you probably know, GANS are generative adverserial networks; key words - GENERATIVE and ADVERSERIAL. It is a special class of neural network modelling as operates on the basis of adverserializing outputs between the generator and the discriminator.

What do we mean by Generator and Discriminator?
One could think of a GAN as two models working in an adverserial manner. The generator, used/trained to generate fake data - and the discriminator, used/trained to differentiatet the fake generated images of the generator from the ground truth dataset given. The goal of the generator is to create images that are indistinguishable from the ground truth dataset. So in that sense, we could think of the discriminator as some quasi loss function; iteratively shifting the generator to a local minimum over its loss landscpe/ latent space of outputs until an optimal output can be produced. Both models are trying to “outsmart” each other, so as the generator get’s better, the discriminator also improves.
Depending on the complexity of the product we are trying to implement, the GANs can either be implemented by some fairly simple feed-forward network, or as complexity increases, a convolutional network, or some more complex network like a U-net.
** Add eqns here
BACKGROUND (How do these little guys even work?)
Following a simple example that Ian Goodfellow (the inventor of GANs uses to explain the models), we could imagine the generator as some sort of master forger; think Abagnale from catch me if you can. And we can imagine the discriminator as detective Hanratty, trying to catch the forger in action. The main caveat here is that we would like the detective (discriminator) to scale in detection skill as well as Abagnale (generator) scales in forging skill.
lets take a closer look into how these actually work.
Maximum likelihood estimation
Generally speaking not every generative model makes use or is based on maximum likelihood estimations. But, today we are lookinga at GANs, and guess what? they do make use of MLEs! MLEs are a subcompartment of the underlying mechanism of GANs. So what is an MLE? you could think of an MLE as a model that outputs an estimation of a probability distribution over a parameter denoted that maximizes the likelihood of a certain output y. Think of it as an argmax.
we can write the MLE as:


By maximizing the likelihood of a model outputing the probability distribution over the parameter , we simultaneously minimize the KL (Kullback-Leibler) divergence (kl divergence is just a quasi distance measures between probability distributions. Based on entropic load difference between distribution P and reference distribution Q. ie, a relative entropy of 0 indicated the two distributions in question have indentical quantities of information. KL divergence is just the average difference in the number of bits required to encode samples of P, using code optimized for Q rather than one optimized for P) between the data generator distribution and the model distribution, which is equivalent to maximizing the log-likelihood (loss?) of the training set.
Recall: Minimizing the KL divergence between  and
and  is exactly equivalent to maximizing the log-loklihood of the training set
is exactly equivalent to maximizing the log-loklihood of the training set

A taxonomy of deep generative models
Here is an illustration of the taxonomy of generative models. The aim is to gain a better intuition for how these function and interplay with other non-MLE based methods and other such complex models.
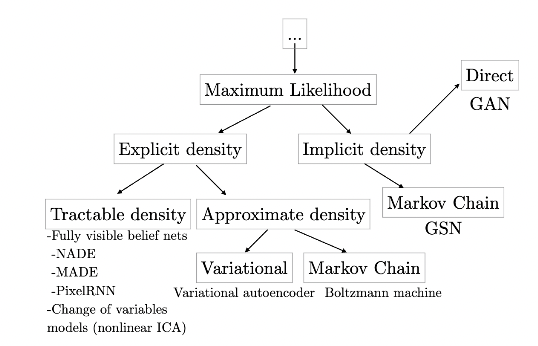
Variational(deterministic) vs Markov Chain apps(stochastic)
Explicit models requiring approximation, due to some caveats of intractible density functions, we have to decide between two approximation methods. We have deterministic approximation methods, which is primarily applied to variational methods, and we have stochastic methods, which are applied to Markov chain methods, as well as Monte Carlo methods.
Lets take a quick, simple look at variational approximaiton methods
All we need to know about variational methods is that they define a lower bound for many famileis of models, allowing it to define a loss function L that is computationally tractable even when the log liklihood is not. As some of you might already know, the most popular, or at least, most functional variational learning method in deep generative models is the Variational Autoencoder (VAE). VAEs are one of the main approaches to generative modelling in deep learning. The primary constraint though, of VAEs is that, when too weak of a prior/posterior distribution is used, even when other condition are optimal (ie, optimization algorithm, infinite training data, etc), the gap between L and the true likelihood can result in the approximator of the model learning something other than the true distribution of data (ie overfitting/underfitting), meaning that convergence won’t be optimally achieved.
Recall: Variational methods define a lower bound

Now let’s take a look at Markov Chain approximation methods
Now, this is where it gets fun! Most of deep learing operates in a stochastic approximative rather than deterministic approximative probabilistic landscape. The same applis to GANs. A markov chain, as applied to generative models imples repeatedly drawing/updating a sample x according to some transition operator q seemingly sometimes gauranteeing that x will eventually converge to a sample from the distribution of the dataset X.
Recall: A Markov chain is a process for generating samples by repeatedly drawing a sample  .
.
Ok, now that we’ve covered most of the theoretical background of generative models in general, let’s go specifically into GANS
GAN Framework As we saw earlier, GANs run on an adverserial basis where a generator (forger) has to continually attempt to outsmart a discriminator (detective) as both of them are fairly linearly dependent on the other for iterative improvement.
Both “players” the generator and the discriminator are models in their own right, meaning they are both differentiable, meaning they both possess individual loss functions that can both be backpropagated through. The Generator can be defined by a function G that maps